Про нейминг и организацию кода в шарпах и в лиспе
Все что ниже - по просьбе; мое личное мнение, под мое сегодняшнее видение ситуации. Может быть, через полгода я буду смотреть на это как на бред сумасшедшего. Какие бы ни были приняты правила - пускай даже самые дикие - их наличие значительно лучше их отсутствия.
На всякий случай - если будете кликать на картинках, открывайте их в новой вкладке.
Есть правило: разрабатывая код, помните: вполне вероятно, что код будет читать психопат с бензопилой и дробовиком, который знает, где Вы живете. Возможно, это будете Вы.
Соответственно (независимо от языка):
- однобуквенные переменные возможны только если они используются не более чем в 3..5 строках. В крайне редких случаях допускается количество строк увеличить до 10, дальше – х`генушки.
- любая переменная должна своим именем показывать, что в ней хранится. Слой? layer. Примитив чертежа? entity. Определение блока? Почему б не block_def / blockDef? Ну и тому подобное. То же самое касается и имен методов / функций: имя должно показывать, что эта хрень вообще делает. Имя в лиспе mxm вряд ли можно назвать информативным, а вот matrix-multiply-by-matrix уже подскажет самим своим именем, что выполняется умножение матрицы на матрицу. Точно так же GetBD и GetBlockDefinition немного сильно разнятся по своей информативности. Не стоит экономить на нажатиях клавиш!
- код повторяется больше одного раза? Выносить его в приватный метод (NET) / локальную функцию (lisp)
- код занимает больше экрана или выполняет вполне себе законченную логическую операцию? Выносить в приватный метод (NET) / локальную функцию (lisp)
- если код на шарпе, то приватные методы / поля / свойства скидываются в конец кода класса, а первым идут конструкторы класса. В лиспе придется локальные функции бросать вперед, иначе код тупо не заработает
- все документировать. Все что можно и что нельзя. Вспомнить, что творит какая-то функция, через полгода будет практически нереально
- стараться минимально привязываться к глобальным переменным. Любой метод / функция должен(на) работать только с тем, что ей передано
- если количество параметров вызова превышает 3 штуки, стоит подумать, как от такого стоит избавиться. А избавиться на самом деле не так уж и сложно
 Передаем либо экземпляр класса (NET), либо список (lisp)
Передаем либо экземпляр класса (NET), либо список (lisp)
В качестве иллюстрации приведу кусок фейкового кода по нормализации блоков чертежа (не факт что текущего). Попробуйте оценить, насколько он читабелен. Код на лиспе:
1 2 3 4 5 6 7 8 9 10 | ;; Тупо для иллюстрации, поэтому переменные / функции / ... не локализую (defun _kpblc-block-normalize (doc param-list) (setq block_def_list (fun_get-block-definitions (vla-get-blocks doc))) (setq layer_status (fun_unlock-thaw-layers (vla-get-layers doc))) (foreach block_def block_def_list (fun_normalize block_def param-list) ) (fun_restore-layers doc layer_status) ) |
Мне кажется, что такой код читать будет значительно проще, чем многостраничный: получили описания блоков, определили состояние слоев (разблокировав и разморозив их по ходу дела), прошлись по каждому описанию, как-то нормализовали, восстановили состояние слоев.
При всем при этом есть еще одно правило в лиспе, которое я стараюсь соблюдать: любая локальная функция может быть вытащена наружу в любой момент и протестирована в отрыве от своего “владельца”.
Во-первых, до этих настроек надо добраться. В поле поиска вколачиваю “имен”:
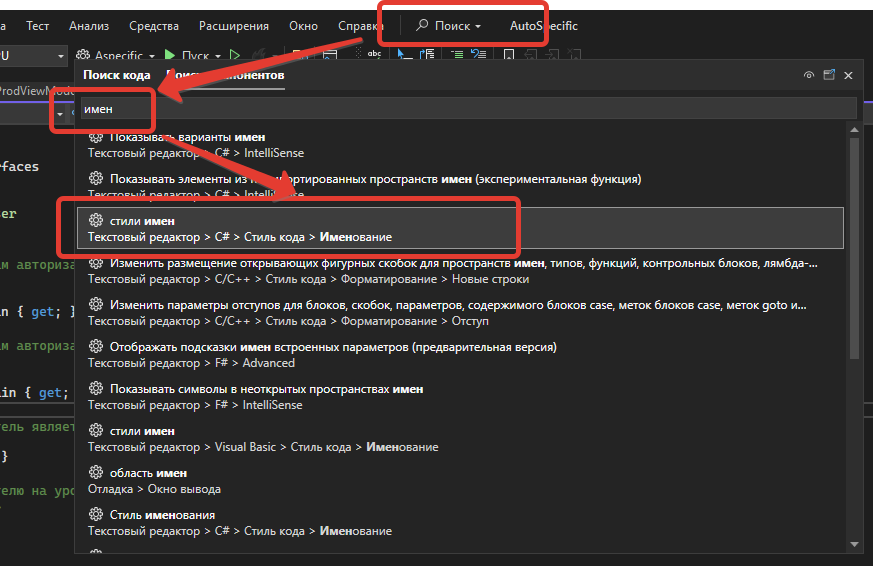
На старте получаю нечто типа:
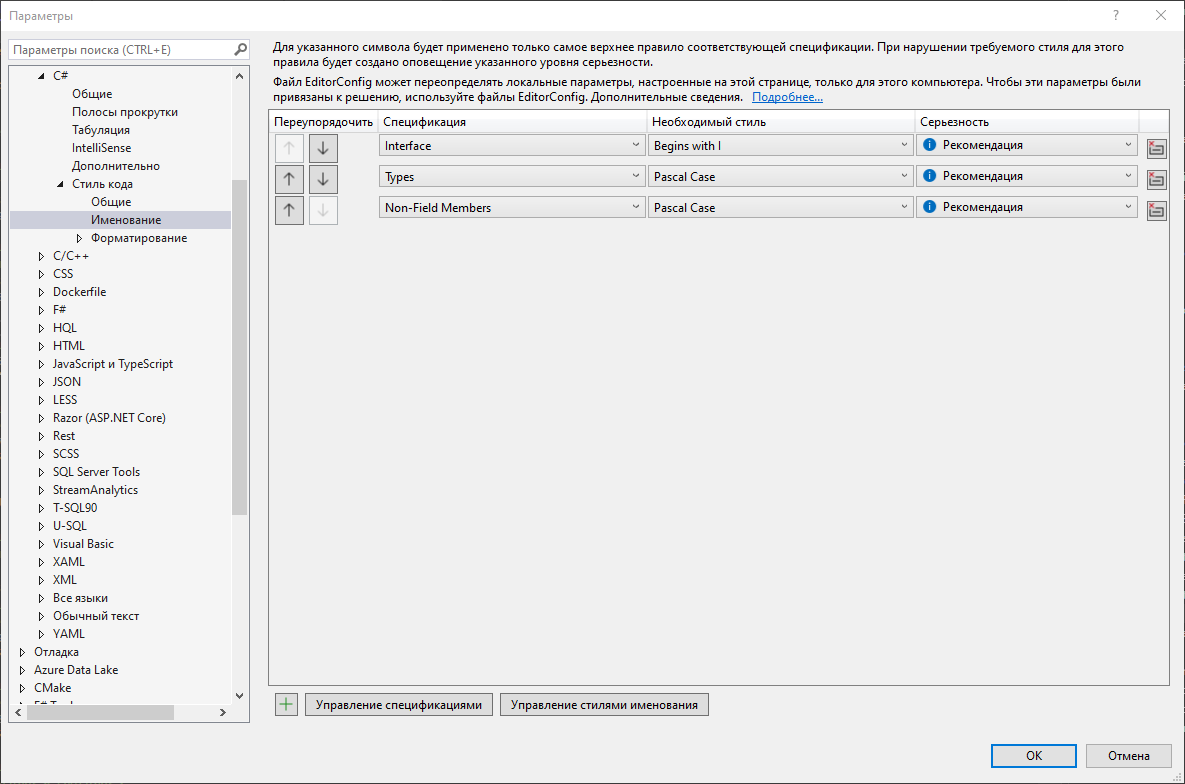
Дополняя этот список, можно, во-первых, указать, что именование может быть не рекомендацией, а критическим багом / ошибкой, а заодно указать правила именования всего чего угодно:
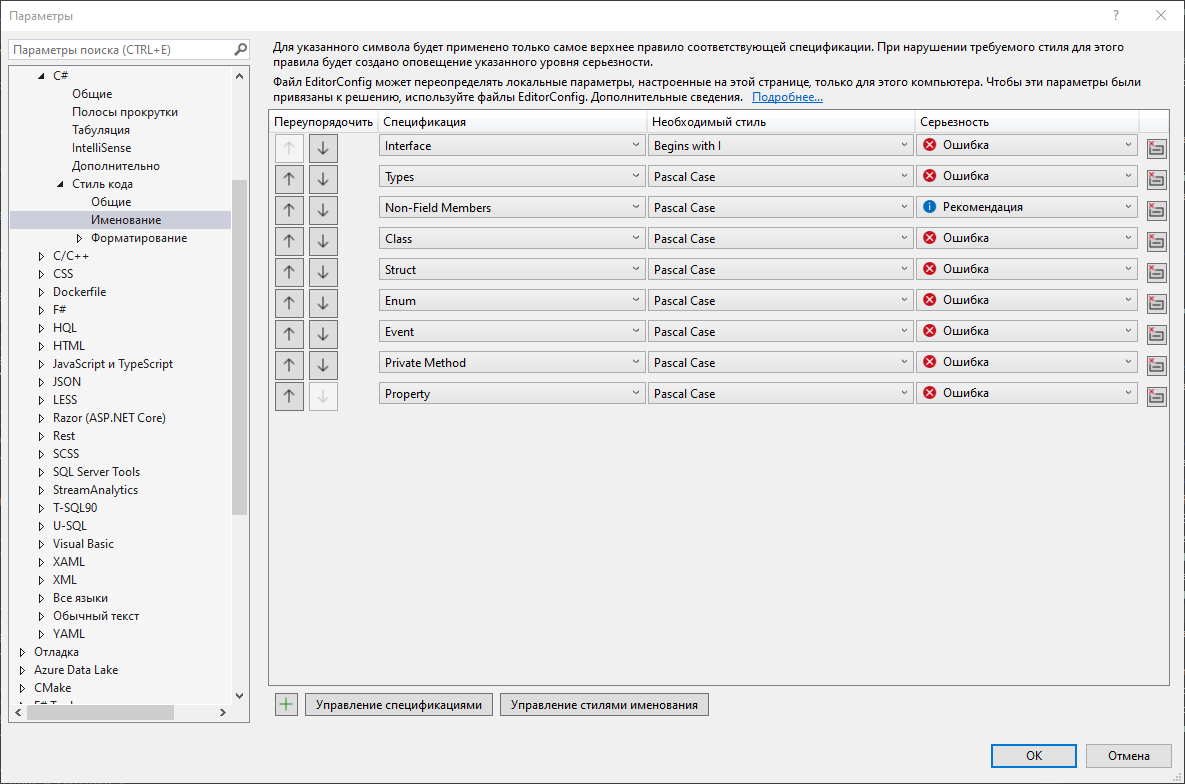
К сожалению, сама VS “по умолчанию” предоставляет мало возможностей для контроля именований локальных переменных, переменных уровня класса и тому подобное. Но и такое уже лучше чем ничего. С другой стороны, кто мешает свои стили создать?
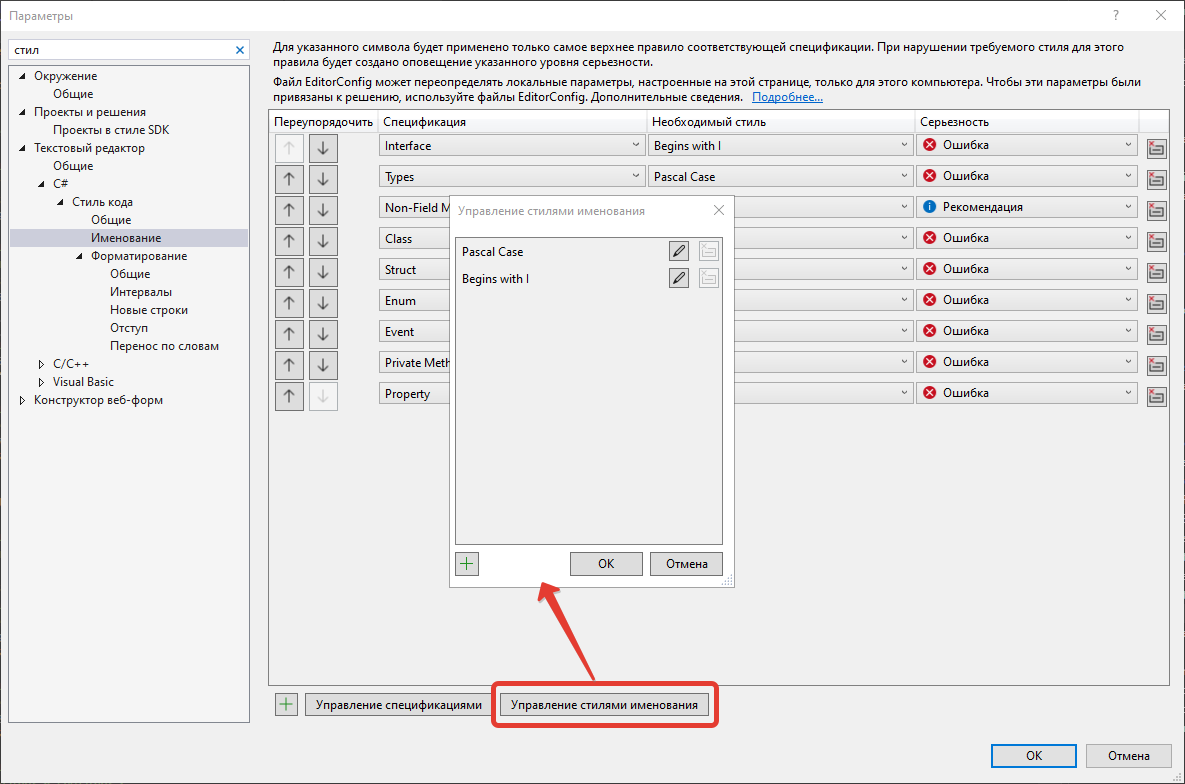
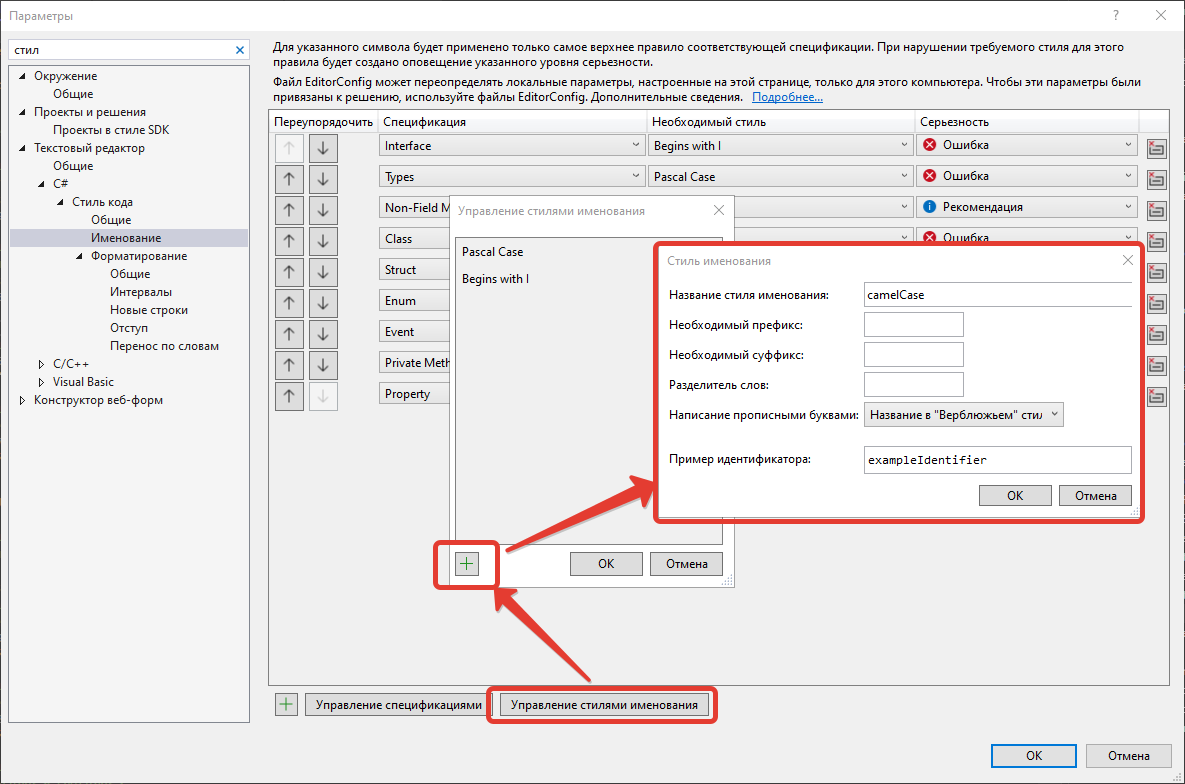
Поиграться можно, и, может быть, даже чего-то добиться )))
Теперь мои правила по именованиям переменных / констант / методов / классов / …
- Имена интерфейсов начинаются с символа “I” (заглавная “i”)
- Имена классов – PascalCase, т.е. начинаются с заглавной буквы. Значимые слова просто начинаются с заглавной буквы. К примеру, класс CurrentUser должен работать / показывать / возможно, менять что-то, что касается текущего пользователя. И ничего более
- Имена методов класса – тоже PascalCase. Т.е. CurrentUser.RegisteredLogin, CurrentUser.CanSaveToDbase и т.д.
- Имена параметров – опять же PascaleCase. Т.е. CurrentUser.CanLog(string LogFileName). Если что – в официальных рекомендациях идут camelCase. Но мне с таким работать показалось не очень удобным
- Имена локальных переменных внутри любого метода – camelCase. Т.е. string someValue = "abc" и тому подобное
- Имена локальных констант – UPPER_CASE. К примеру, internal const int ARMATURE_LENGTH_COLUMN = 15;
- Имена переменных уровня класса – _camelCase. Например, private int _armature_range;
- Перечисления могут в своем имени содержать слово Enum. А могут и не иметь. Но ошибкой это точно не является
Вроде ничего критического не упустил…
Кстати, об именах переменных ![]() Лично я считаю ненормальным в имени переменной указывать ее тип. Т.е.
sBlockName я заменю на
blockName – имя уже показывает, что в ней болтается имя блока. Т.е. 100% строка.
iRange преобразовывается в
range, ну и так далее.
Лично я считаю ненормальным в имени переменной указывать ее тип. Т.е.
sBlockName я заменю на
blockName – имя уже показывает, что в ней болтается имя блока. Т.е. 100% строка.
iRange преобразовывается в
range, ну и так далее.
Подобное может иметь смысл в языках с динамической типизацией, но в шарпе?..
Ну ок, чистую VS разобрали плюс-минус, двигаюсь дальше.
Под VS есть масса дополнений, и одно из моих любимых – Resharper от JetBrains. Методы скачивания / установки / активации расписывать не буду, их и так тьма. Проблема в том, что после установки и активации этого расширения его настройки “перекрывают” настройки VS:
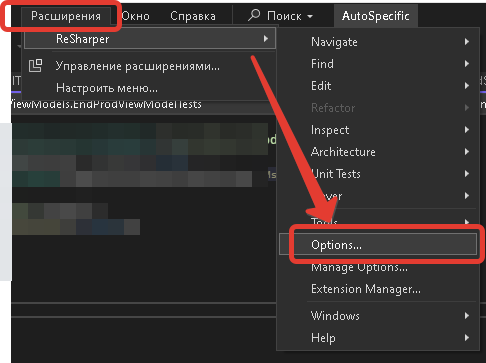
И вот тут уже возможностей немного больше прям на старте:
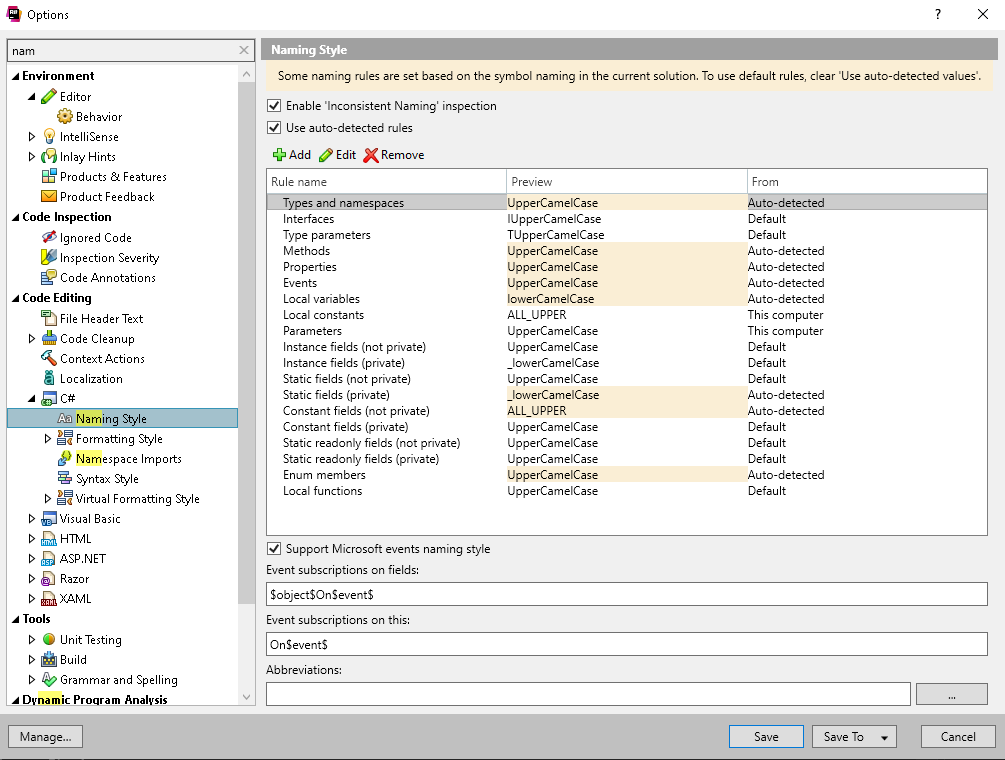
Соответственно, выполнив настройки и слегка поигравшись с собственным кодом, можно много всякого интересного узнать о себе и качестве именования ![]()
Лисповой код лично у меня редко бывает коротким и слабовложенным (хотя иногда так хочется все поменять!). Так что в VLIDE настройки у меня обычно такие:
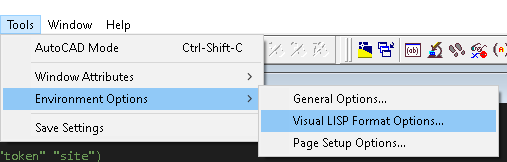
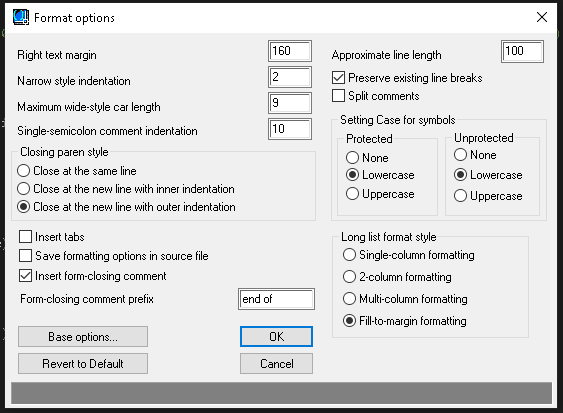
Такие настройки позволяют форматировать код в плюс-минус читаемый вариант (сугубо ИМХО!)
Для VSCode + AutoLISP настройки расширения поставил такими (худо-бедно работают):
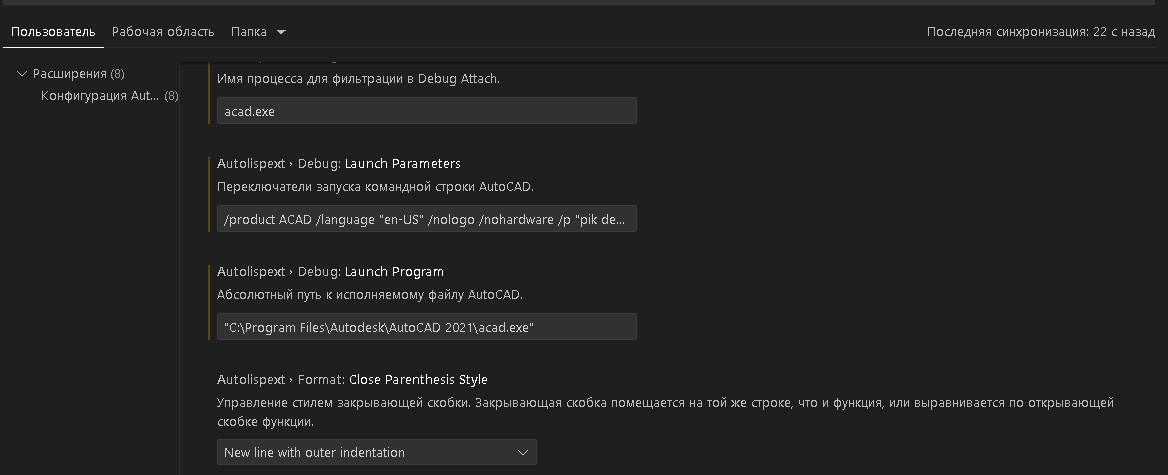
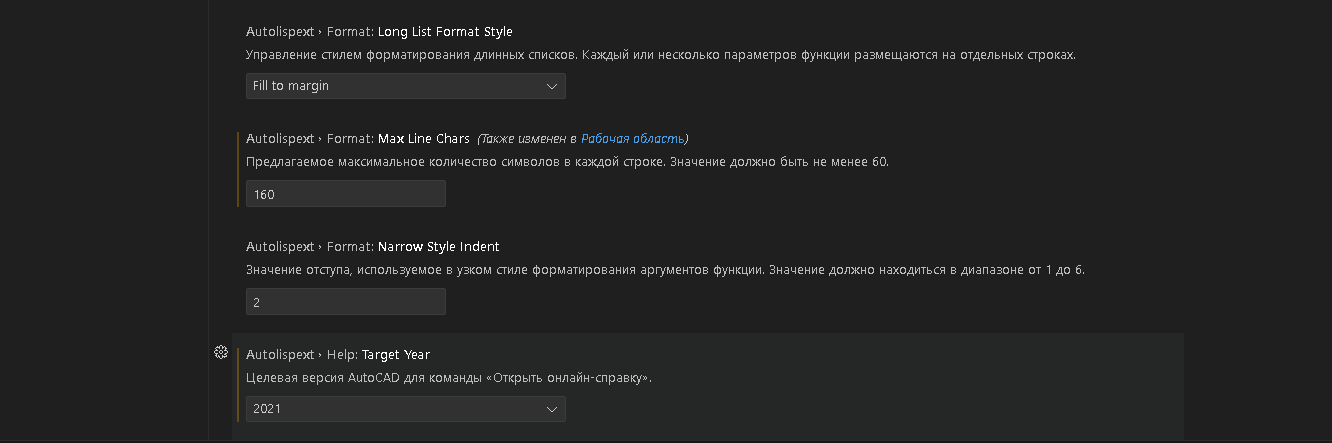
Ну и туда же: глобальные функции предваряются _kpblc. Символ подчеркивания означает, что это вообще функция, и она что-то возвращает. Дальше идет описание из слов на английском языке. Значимые слова разделяются символом “-“.
Т.е., например, функция конвертации чего-то в строку будет иметь имя
_kpblc-conv-value-to-string. А преобразования чего-то в ename-указатель –
_kpblc-conv-value-to-ename. Ну и тому подобное